NanoTwitter Porfolio Page
Team
Akiba Sato, Kevin Wang, Meg Kobashi
Overview
This application is a miniature version of Twitter. Users can post tweets and explore other users' profiles and tweets. Our primary focus for our project was scaling, and used various techniques such as caching, multiprocessessing, and service oriented architecture to achieve maximum performance when getting a high load of requests. In this report, we detail the various scaling techniques and report real results from executing load tests performed with loader.io.
Tech Stack
- Node.js
- Express
- Redis
- Postgres
- Sequelize (Postgres ORM)
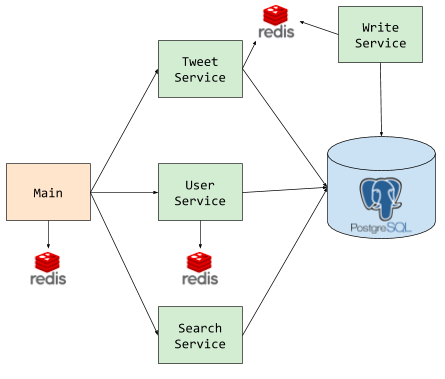
System Components
- Main application
- User service
- Tweet service
- Search service
- Writer service
Scaling techniques
This section contains the scaling techniques we used and their performance improvements. Note that we wanted to make the experiment setup as simple as possible - in some experiments, we only serve the homepage with a single hard-coded tweet. While this does not reflect a realistic scenario and thus is not indicative of our real application performance, we believe this controlled environment was the best to demonstrate the benefits of our scaling techniques.
Server-side caching
1. HTML caching
We used in-memory cache provided by Redis for server-side caching of raw HTML and database objects. The raw HTML was cached to allow the main application to serve a page without contacting any of the microservices, eliminating the HTTP latency. Specifically, the logged-in/logged-out homepage and logged-out user pages were cached. We foresee that Redis capacity can pose a problem for caching user-specific pages; therefore, we implemented a TTL of 60 seconds for the pages.
Note that we are relying on the TTL to evict the page and get the updated view. While this could be concerning if a user wishes to see fresh tweets right away, we decided that the user experience would not take a hit as long as the user sees their own tweets right away. Therefore, the choice of the pages to cache is justified: the user is unlikely to visit the logged-out homepage and their own logged-out user page after tweeting; the logged-in homepage for the user only displays the followees’ tweets, not the user’s tweets.
The performance benefits are clear - the average response time decreased by ~35%, and the number of successes increased by ~157%.
GET /
Maintain Client Load: 0-2000 clients
Before:
After:
2. Database object caching
We also cache database data on the microservice that is responsible for serving that object to the main application. Some of the data include user profiles and timelines, which is a list of tweets that the user sees on user pages and the homepage. Querying for the timelines on Postgres can be expensive; therefore, this is cached as a queue in Redis. When there is a new tweet, the oldest tweet would be evicted.
Client-side caching
We also employed client side caching of static assets such as CSS, images, etc. with a TTL of 2 hours.
Clustering
We increased the number of processes running on each dyno by increasing the Heroku configuration variable WEB_CONCURRENCY from the default value of 1 to 5. This helps us optimize dyno usage and allowed greater concurrency for our application. Our average response time decreased by ~40% and the number of successes increased by ~215%.
GET /
Maintain Client Load: 0-2000 clients
Before:
After:
Batch writes and Heroku scheduler
Writing to the database upon every tweet poses a fatal bottleneck for our application, considering tweets take up a large portion of our application data.
Initially, we would insert the tweet into the database and update the timeline caches appropriately; however, since the tweet will still be visible to users with the presence of the cache, the database update logic can be flexible. Therefore, we implemented a batch write service, which polls X number of tweets from the cache periodically and batch writes to the database. Note that this service only handles tweets but can be used for any type of data that requires a large number of writes. This service is hosted on Heroku and configured to run every minute using the Heroku scheduler.
It is possible that the we prematurely cache a tweet that does not conform to our database constraints (e.g. tweet content cannot be null), as we only perform sanity checking when inserting into the database. However, we decided that we should value high availability over correctness.
Models
We introduced indexes on our Postgres data models. Some notable ones include an index on the timestamp of creation for tweets and relationships, so the timeline and list of followers/followees can be efficiently ordered by timestamp upon retrieval.
Users contained columns for number of tweets, number of followers and number of followees. When a tweet or relationship was created or destroyed, the values in the corresponding row for the user would be adjusted accordingly. User info had to be generated at every user’s page, but instead of doing join tables while loading user data, the integer values of those counts were shown instead. When a follow was generated or destroyed, asynchronous communication pushed the follow request and count incrementation/decrementation and artificially adjusted the count on the user page through AJAX.
Asynchronous communication
Due to the asynchronous nature of Node JS, async calls are incredibly easy to make so that if, for example, two pieces of data can be pulled from the database or cache in parallel. However, it’s necessary to ensure that the appropriate promises or callbacks wait until completion to then progress to avoid race conditions.
Parallelizing and removing expensive packages
Whenever a client sends a request, their request is passed through a pipeline of middleware. They are merely functions that make changes to the request object before passing it to the routers.These functions can be expensive, slowing down the request-response cycle before even reaching the main application logic. Initially, we were executing these middleware sequentially, but we parallelized these calls using the Node async package. The average response time improved by ~53%, and the number of successes improved by ~190%.
We also found that Express sessions and Passport authentication middleware were bottlenecks for many applications. We decided to create a custom session management system using redis and manually setting browser cookies. This caused a lot of lost engineering time and refactoring, since the mechanics of authentication were completely abstracted by packages before; however, this gave us greater control over the data that we store in sessions.
GET /
Maintain Client Load: 0-2000 clients
Before:
After:
Design alternatives
MongoDB
Various Node JS tutorials suggest implementing MongoDB, a NoSQL store, as the database due to the general ease of implementation and various existing documentation. We went with Sequelize, a promise-based ORM, and its PostgresSQL dialect, due to the nature of the difficulty of joins between Tweets and Users, for example, in a document-oriented storage, and due to the structure of the project.
Multiple Dynos
One way that we could have improved performance is by using mulitple dynos to support more concurrency with our various requests. Throughout this semester and the final week when we ran the loader tests, we saw good performance for the team that used multiple dynos to balance the load of the applicaiton. However, one trade off with using multiple dyanos was that we would have to use multiple routes, define the setup for each dyno, and do a project for x number of dynos. In addition, since each dyno is located across a seperate server, we would have to consider whether or not to partition the database. Since there would be much more requests coming in that suceed, there would be a bottlneck from either fetching from redis or writing to the database.
Final performance
GET /
Maintain Client Load: 0-2000 clients
Before:
GET /user/testuser
Maintain Client Load: 0-2000 clients
After:
POST /tweet/new
Clients per test: 1000 clients
Future improvements
Fragmentation
The Sequelize ORM doesn’t support neither horizontal nor vertical fragmentation. In our app, due to the generally small-scale, it’s not so simple to know where to horizontally split due to lack of data. On the other hand, vertical fragmentation would have allowed for less costly joins depending on what data is fragmented and needed. If the ORM supported it or if there was a switch that one that allowed it, it would add another level of scalability.
RabbitMQ
With a structured message broker system like RabbitMQ, a middleman can be generated between services to reduce load and delivery times since this would perform these tasks as opposed to the app.
Links
Github Repo
Scalability Presentation on Node.js